작업 배경
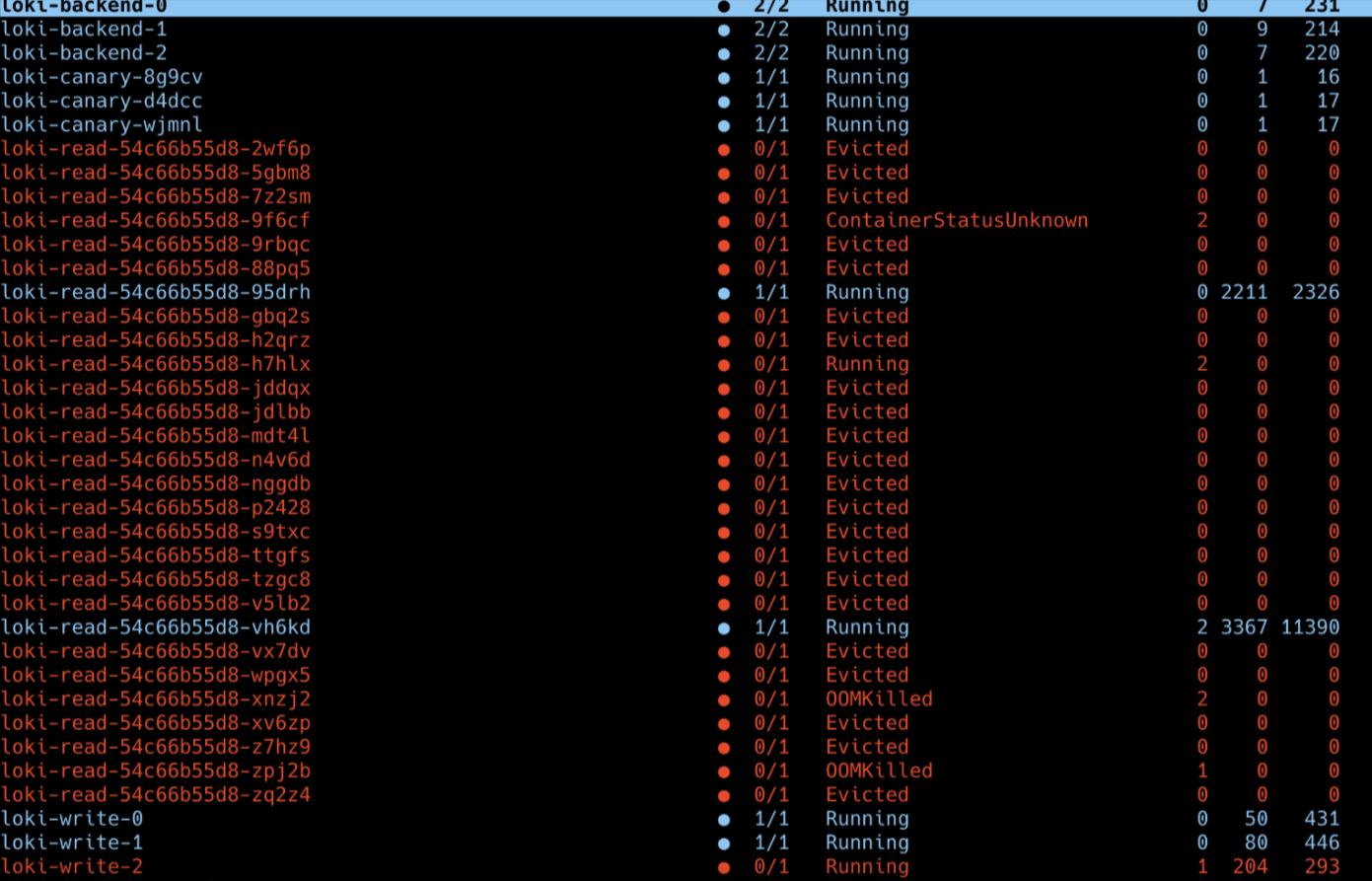
로키를 적용한 후 간헐적으로 loki-read 컴포넌트가 죽으면서 로그 조회가 불가해지는 상황이 발생했습니다. 이에 로키 구성을 확인해보니 deploymentMode 가 SimpleScalable<->Distributed 로, 보통 SSD 에서 Distributed 로 마이그레이션 하기 위한 모드로 올라가 있는 것을 확인할 수 있었습니다. 이 모드에서는 SSD 와 Distributed 컴포넌트들이 모두 올라가있지만 SSD 모드로 동작하여 Distributed 컴포넌트들은 리소스만 크게 점유하고 실질적으로는 사용하지 않는 상황이었습니다.
앞으로 Datadog 대신 사용할 것을 고려하면 사용량이 늘 것으로 예상되어, 안정성을 높이기 위해 Distributed 모드로 전환 작업을 진행하였습니다.
각 컴포넌트 별 관계

- SSD 모드에서는 쿼리가 복잡해지고 로그가 쌓일 수록 read 컴포넌트의 부하가 심해져(limit이 없어서 노드의 최대까지 사용하다가) evicted 되었음.
Distributed Mode 플로우
1. 로그 수집
Distributor → Ingester (메모리 청크 + WAL + 청크 캐시)
- 클라이언트 요청
- Prometheus Remote‑Write, Grafana Agent, 또는 OTLP 등으로부터 로그/메트릭이 HTTP POST(grpc_listen_port: 9095 또는 http_listen_port: 3100)로 들어옵니다.
- Distributor
- distributor.ring.kvstore.store=memberlist 기반의 링을 사용해, 3개의 Ingester 중 하나 이상(복제 인자 common.replication_factor: 3)으로 데이터를 분산 전송합니다.
- pattern_ingester.enabled=true 설정 덕분에, 로그 스트림 패턴 단위로 어느 Ingester가 담당할지 결정하고, 스트림별로 같은 인제스터에만 보내져 시리즈 일관성을 유지합니다.
- 인제스터(Ingester) & 청크 캐시
- 청크 생성 및 인메모리 보관
- Ingester(ingester.chunk_encoding=snappy)는 받은 샘플을 메모리 상에 청크(chunk) 형태로 모읍니다.
- WAL 쓰기
- wal.flush_on_shutdown=true 로 설정되어, 인제스터가 종료될 때 메모리 청크를 WAL(Write‑Ahead Log)에 먼저 플러시합니다.
- 청크 캐시
- chunk_store_config.chunk_cache_config 로 지정된 외부 Memcached(loki-chunks-cache)에 청크를 저장·조회합니다.
- 백그라운드 워커(writeback_goroutines:1)가 버퍼 단위(writeback_buffer:500000, writeback_size_limit:500MB)로 캐시에 반영하며, 이후 디스크나 S3에 영구 저장을 진행합니다.
- 청크 생성 및 인메모리 보관
2. 스토리지 적재
TSDB 블록 생성 → S3 업로드 (boltdb_shipper/tsdb_shipper)
- TSDB 블록 저장
- schema_config에서 정의한 기간(period:24h) 단위로 TSDB 블록을 생성하고, storage_config의 S3(stclab-loki-chunk 버킷)에 업로드합니다.
- BoltDB Shipper & TSDB Shipper
- 인덱스 블록은 boltdb_shipper 또는 tsdb_shipper를 통해 S3에 적재됩니다.
- index_gateway를 Simple 모드로 사용하여, Querier에서 필요 시 인덱스 블록을 S3에서 직접 조회합니다.
3. 쿼리 요청
Query Frontend (결과 캐시) → Querier (Ingester/S3 조회)
- Query Frontend
- 클라이언트의 LogQL HTTP 요청을 받아
- queryScheduler 에 분할 작업을 요청하고,
- frontend.tail_proxy_url(Querier)로 tail(실시간 스트리밍) 요청도 프록시합니다.
- 클라이언트의 LogQL HTTP 요청을 받아
- 결과 캐시
- query_range.cache_results=true 설정 덕분에, 쿼리 결과 전체를 loki-results-cache Memcached에 캐싱합니다.
- 첫 요청 시 백엔드에서 계산한 결과를 캐시에 쓰고(default_validity:12h), 이후 같은 쿼리는 12시간 동안 모두 캐시 히트만으로 응답합니다.
- Querier
- querier.max_concurrent:10 만큼 동시 쿼리를 수행하며,
- 스트리밍 모드와 range 쿼리에 따라 각각 Ingester(메모리)와 S3 TSDB 블록을 조회해 결과를 조합합니다.
4. 룰 평가
Ruler (LogQL 평가 → Alertmanager)
- ruler.enable_api=true로 API가 활성화되어 있어, Ruler가
- S3 버킷(stclab-loki-ruler)에서 룰 파일을 읽고,
- 주기적으로 LogQL 표현식을 평가해
- alertmanager_url(mgmt-observability-mimir-gateway)로 알림을 전송합니다.
- Ruler 자체에도 WAL(/var/loki/ruler-wal)을 두어, 장애 복구 시 마지막 상태를 보존합니다.
5. 블록 정리
Compactor (S3 블록 병합)
- common.compactor_address를 통해 컴팩터가 Ingester → S3 업로드 블록을 주기적으로 병합(compact)합니다.
- 오래된 블록 정리와 out‑of‑order 데이터 합치기를 수행해 스토리지 효율을 최적화합니다.
distributed mode 전환
순서:
- SSD 모드로 deploy
- SimpleScalable<->Distributed 모드 전환, SSD, Distributed 모드에 속하는 컴포넌트 모두 올림
- Distributed 모드 전환, SSD 컴포넌트들 replica 0으로 전환
추가로 고려한 사항:
- Zone Aware Ingesters disable
- AZ 통신 비용을 줄이기 위해 비활성화함
# distributed
ingester:
replicas: 3
zoneAwareReplication:
enabled: false- test: enabled 설정으로 self monitoring 및 canary 컴포넌트 내림
결과:
- gateway cm 변경됨

- loki cm 변경됨
결론
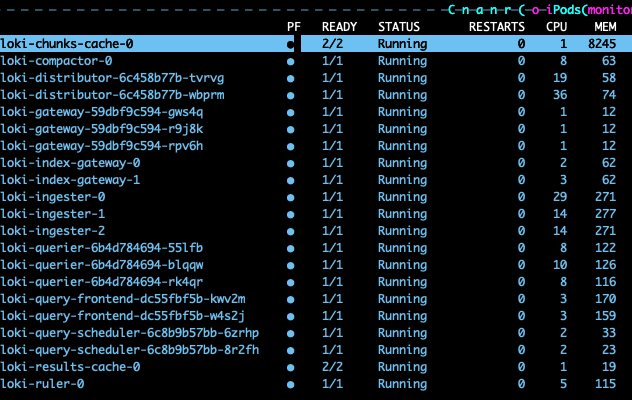
SSD → Distributed 모드 전환 후 기간 설정을 길게 한 쿼리에도 로키 컴포넌트가 죽지 않고 안정적으로 운영되는 것을 확인할 수 있습니다.
![]()

참고
Migrate from SSD to distributed | Grafana Loki documentation